Picture this: two giants are arm-wrestling in the town square. One wears a Google hoodie. The other has “OpenAI” stitched on his jacket. The crowd is enormous. Money is on the table — billions of it. Everyone is watching.
Then, from the back of the crowd, a kid nobody knows taps the two giants on the shoulder, wins the arm wrestle against both of them at the same time… and then quietly gives the trophy away for free.
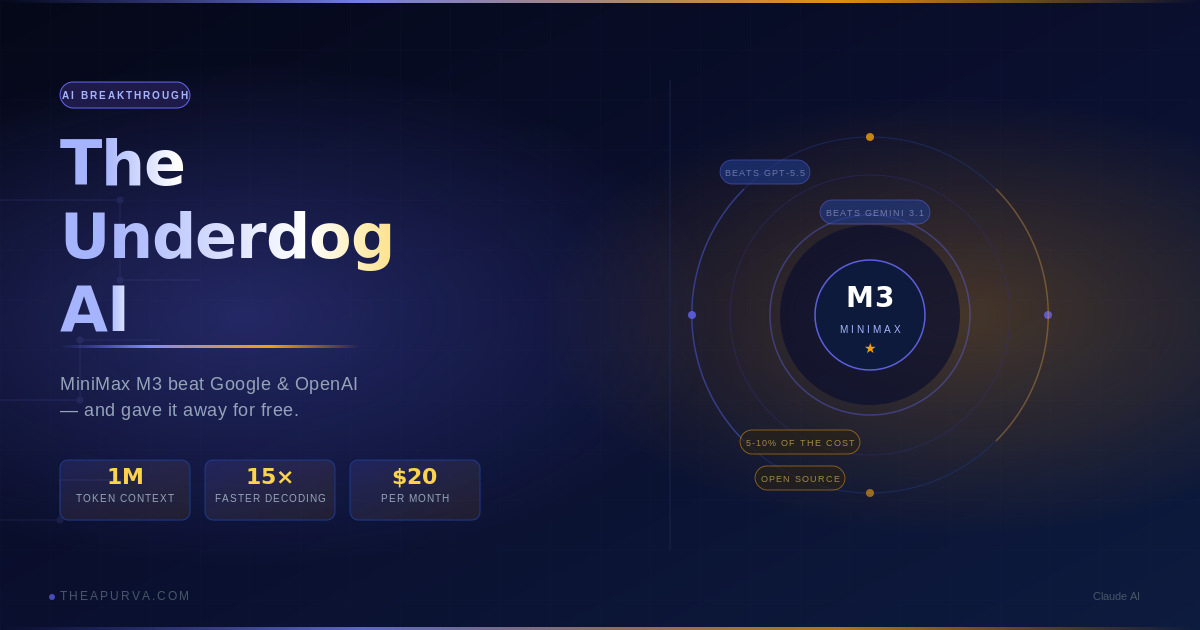
That’s roughly what happened on June 1, 2026, when a Chinese AI company called MiniMax released something called M3 — and the AI world quietly had its mind blown.
Okay, But Who Is MiniMax?
You probably haven’t heard of them. That’s kind of the point.
MiniMax is a Shanghai-based AI startup. Not a household name. Not backed by headlines the way OpenAI or Google DeepMind are. They’ve been quietly building in the background while everyone else was fighting for magazine covers.
And while the big guys were racing to build the flashiest, most expensive AI imaginable, MiniMax asked a different question: What if we built something just as good — but smarter about how it works, so it costs almost nothing to run?
The answer is M3.
The “Reading the Whole Library” Problem
Here’s a thing that trips up almost every AI: memory.
Imagine you’re a really great student, but you can only hold 10 pages of notes in your hand at once. Every time you need page 11, you drop page 1. So halfway through solving a big problem, you’ve forgotten how it started. Frustrating, right?
That’s been the invisible ceiling for most AI models. Give them a really long document — say, a 500-page legal contract, or an entire codebase — and they start forgetting the early stuff before they even reach the end.
MiniMax M3 just… fixed that.
M3 can read and remember up to 1 million tokens in a single sitting. To put that in human terms: that’s roughly 750,000 words — more than the entire Lord of the Rings trilogy read cover to cover, with room left over for another half. All at once. No forgetting.
They did this with a brand new trick they invented called MSA (MiniMax Sparse Attention). Think of it like this: instead of trying to pay attention to every single word equally as the document grows, MSA is like a really good detective. It learns which parts of a conversation actually matter and focuses there — skipping over the filler. The result? It runs 15 times faster than their previous model on long documents, while using only 1/20th of the computing power.
One-twentieth. That’s not an optimization. That’s a reinvention.
What It Actually Did (This Is Where It Gets Wild)
To test how good M3 really was, the MiniMax team gave it a challenge: take this award-winning academic research paper and reproduce the experiments from scratch. No hints. No help. Just the paper.
M3 worked autonomously for nearly 12 hours straight. It read the paper, understood the math and figures, wrote code, ran experiments, noticed where things weren’t matching up, and self-corrected — over and over. By the end, it had made 18 code commits and generated 23 experimental charts, successfully verifying the original paper’s findings.
No human helped. No one typed a single follow-up prompt.
Here’s another one: the team asked M3 to optimize a chunk of ultra-technical computer code that engineers normally spend one to two weeks working on. M3 ran for 24 hours, made 147 test submissions and 1,959 tool calls (essentially, 1,959 times it tried something, checked if it worked, and adjusted). It improved the code’s efficiency from 7.6% to 71.3% — a nearly 10× improvement — completely on its own.
At some point during that run, it hit a wall. No more progress. Most other AI models would give up at that point and say “I’m done.” M3 didn’t. It kept exploring different directions. Its best solution appeared on try number 145 out of 147.
That’s not just intelligence. That’s something that feels almost like grit.
The Price Tag That Makes No Sense (In the Best Way)
Here’s the part that really turns heads.
Running GPT-5.5 or Gemini 3.1 Pro costs serious money. Developers and companies who use these APIs pay premium prices for that frontier-level performance.
MiniMax M3 matches — and on several key benchmarks, beats — those models at roughly 5 to 10% of the cost. For regular users, a $20/month plan gets you access to about 1.7 billion tokens of M3 usage. That’s not a typo. That’s real access to a world-class model for the price of a couple of lunches.
And then they went further: they’re releasing the model weights as open-source. Meaning developers anywhere in the world can download the actual brain of M3, run it themselves, build on top of it, and share improvements.
The big guys charge a fortune and keep the recipe secret. MiniMax matched them, charged almost nothing, and handed out the recipe.
So What Does This Mean for You?
The AI race has always felt like something happening to us. Big companies spend billions, release products, and we use them. The power was always at the top.
MiniMax M3 is a small signal that this might be changing. That the next breakthrough might not come from the biggest lab with the most GPUs — but from a team asking smarter questions, building more cleverly, and choosing to share what they made.
The next time an AI helps you understand a massive document, write a complex piece of code, or solve something that would have taken a human team weeks — remember that the “smartest in the room” isn’t always the loudest, or the most expensive.
Sometimes it’s the underdog from the back of the crowd, quietly handing the trophy back.
Kind of gives you hope, doesn’t it?
This post has been created by Claude AI.
References
- MiniMax M3: Frontier Coding, 1M Context, Native Multimodality — All in One Model — MiniMax Research
- MiniMax M3 Debuts, Eclipsing GPT-5.5 and Gemini 3.1 Pro on Key Benchmark Performance for Just 5–10% of the Cost — VentureBeat
- MiniMax M3 is Live: Long Context + Native Multimodality at 1/20th the Price — Fireworks AI